Exploring Pinecone and Qdrant
📌 A Hands-On Review
Introduction
The surge in interest surrounding Vector Databases, driven by the LLM (Large Language Models) boom, has prompted us to share our firsthand experiences with two notable players in the field: Pinecone and Qdrant.
Pinecone
Company Overview
Pinecone, a vector database service, is brought to us by the Pinecone company. Established in 2019, this Californian-based company entered the scene relatively early and has its headquarters in the United States. As of the time of this writing, Pinecone has successfully secured $100 million in capital through its Series B funding round, an impressive feat. A quick glance at their customer page reveals a growing user base.
Production
Pinecone offers its Vector database as a cloud service, currently running on Google Cloud Platform (GCP) and Amazon Web Services (AWS), with plans to expand to Microsoft Azure in the near future. Additionally, Pinecone provides an on-cloud solution, allowing users with their own cloud infrastructure (GCP or AWS) to deploy Pinecone by renting their Virtual Machine image (AMI on AWS). This approach grants users greater control over both infrastructure and data management.

Using Pinecone Service: A Simple Guide
Getting started with the Pinecone service is remarkably user-friendly, even if you're unfamiliar with vector databases. Essentially, it involves just three straightforward steps:
Registration: Begin by signing up for the Pinecone service to obtain your API key.
SDK Installation: Pinecone offers a Python Software Development Kit (SDK) for your convenience. You can easily install this SDK using the command pip install pinecone-client.
Code Implementation: Write your code using the Pinecone SDK. For reference, you can find example code right here.
Feature for Organizing Databases
When delving into the world of Vector databases, one of the initial decisions we face is how to effectively group our data, whether it's by personal information, company details, or project specifics. Pinecone simplifies this process by introducing the concepts of Index, Namespace, and Metadata.
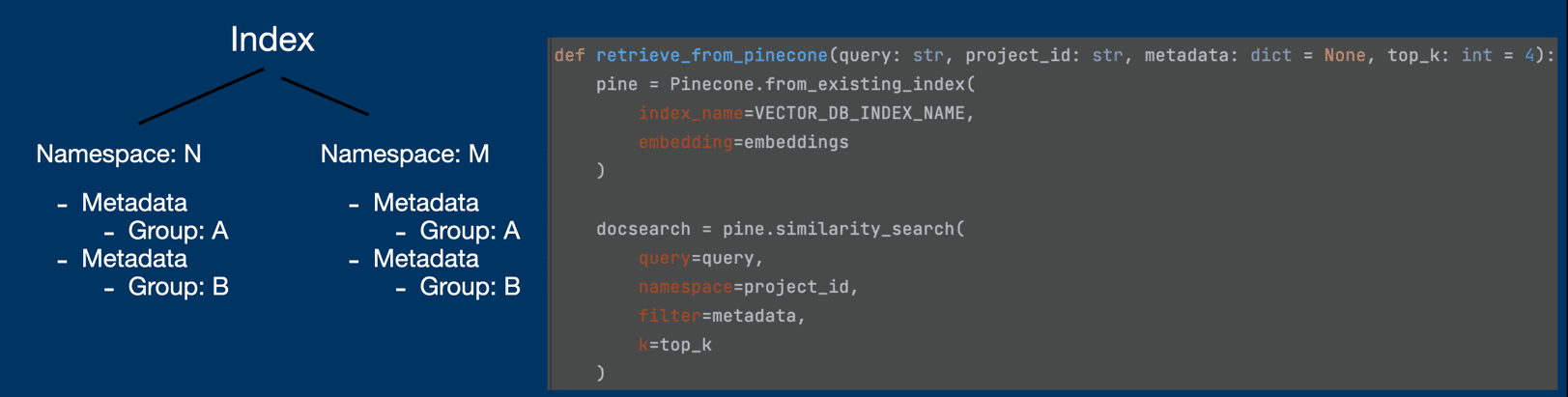
At the top of this hierarchy is the Index, which essentially functions as a database. Remarkably, you can set up different Indexes for various purposes, each with its own specifications.
Within an Index, you can create multiple Namespaces. A Namespace serves as a container for grouping data. It's important to note that queries cannot span multiple Namespaces. For instance, if you want to retrieve results from both Namespace A and B, you'll need to send two separate queries, as illustrated in the diagram below.
To further categorize your data, Pinecone offers Metadata, which consists of key-value pairs that can be attached to each data entry. When executing queries, you have the option to specify Metadata as a filter, allowing you to refine your data retrieval process.
Pros and Cons of Pinecone
Pros:
User-Friendly: Pinecone offers ease of use, making it accessible even for those without prior knowledge of vector databases.
Cloud-Native: Being a fully cloud-native service, Pinecone eliminates the need to worry about infrastructure management.
Speed: Pinecone stands out as the fastest vector database, as supported by benchmark results.
Performance Focus: Pinecone maintains its impressive performance by limiting storage capacity per instance, which can reduce the vector data size.
Documentation: Pinecone boasts comprehensive and user-friendly documentation, supplemented by a wealth of external materials. The clear and easily understandable documentation played a significant role in our decision to adopt Pinecone.
Abundance of Resources: The internet hosts a multitude of examples and materials for Pinecone. In practice, you can often achieve your goals by simply copying and pasting code snippets.
Educational Opportunities: An Udemy course exists that uses LLM and Pinecone as a practical example, providing a valuable learning resource.

Cons:
Closed Source: Pinecone is not open source, which means it cannot be used on-premises.
Limited Insight: While using Pinecone, there may be instances where it feels like a black box, with limited visibility into the internal processes. This lack of transparency can be challenging when investigating unexpected results in similarity searches.
Limited Local Deployment: Pinecone cannot be deployed on a local PC during development, necessitating the use of cloud-based development instances, which can be less convenient.
Cost Considerations: Pinecone can be relatively expensive, with even the smallest instance costing around $70 per month. If multiple instances are required for development, costs can escalate.
Lack of Roadmap Visibility: The closed-source nature of Pinecone also means that users cannot access the company's roadmap or monitor progress on GitHub, limiting insight into future developments.
Qdrant
Company Overview
Qdrant is a company offering vector database services, making it a noteworthy player in this field. Despite its relatively recent establishment in 2021, Qdrant has quickly made its mark. The company is headquartered in Berlin, Germany, and as of the time of this writing, it has successfully secured approximately $10 million in capital funding.
Production
Qdrant's core product is a vector database service, currently operational on Google Cloud Platform (GCP) and Amazon Web Services (AWS), with plans for expansion to Microsoft Azure in the near future. What sets Qdrant apart is its flexibility, offering both on-cloud and on-premise solutions. Moreover, Qdrant's open-source code allows users to run it in various environments, inluding their personal laptops. Additionally, Qdrant provides its vector database service as a Docker image for further convenience.
How to Utilize Qdrant
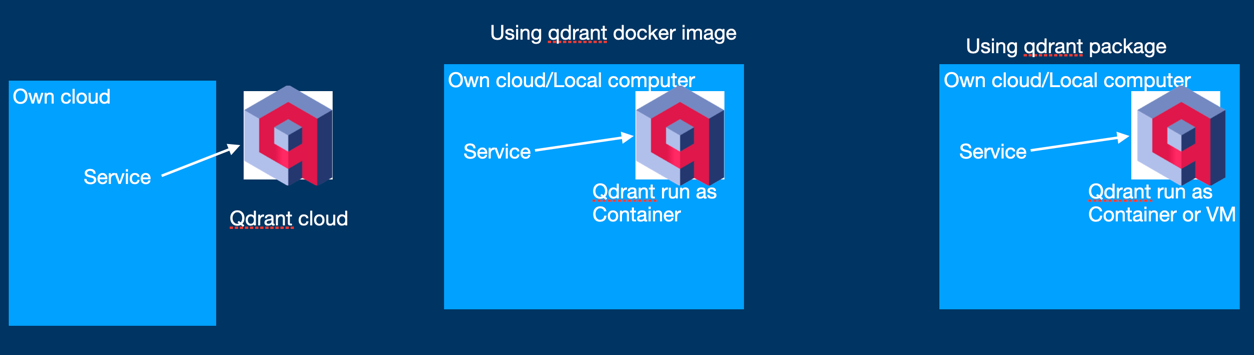
Much like Pinecone, Qdrant offers a cloud-based solution, but for developers, Qdrant's Docker image solution holds particular appeal (as indicated in the image on the left). This enables us to easily run the Qdrant server locally by following these straightforward steps:
- Fetch the Qdrant Docker image and initiate it:
docker pull qdrant/qdrant
docker run -p 6333:6333 qdrant/qdrant
- Install the Qdrant SDK, which is provided in Python:
pip install qdrant-client
- Create code to interact with the Qdrant Docker container as a service.
# embed query
embedded_query = openai.Embedding.create(
input=query,
model="text-embedding-ada-002",
)["data"][0]["embedding"]
# search through vector database
query_results = q_client.search(
collection_name=COLLECTION_NAME,
query_vector=(
vector_name, embedded_query
),
limit=top_k,
)
An intriguing aspect worth noting is the ability to integrate the Qdrant service directly within your code. Qdrant service is encapsulated as a Python package, allowing you to initiate the service within your code according to your preferences. You have the flexibility to store vector data either in memory or in the file system, as depicted on the right side of the image below.
import qdrant_client
q_client = qdrant_client.QdrantClient(":memory:")
# after this, we can insert data and search data

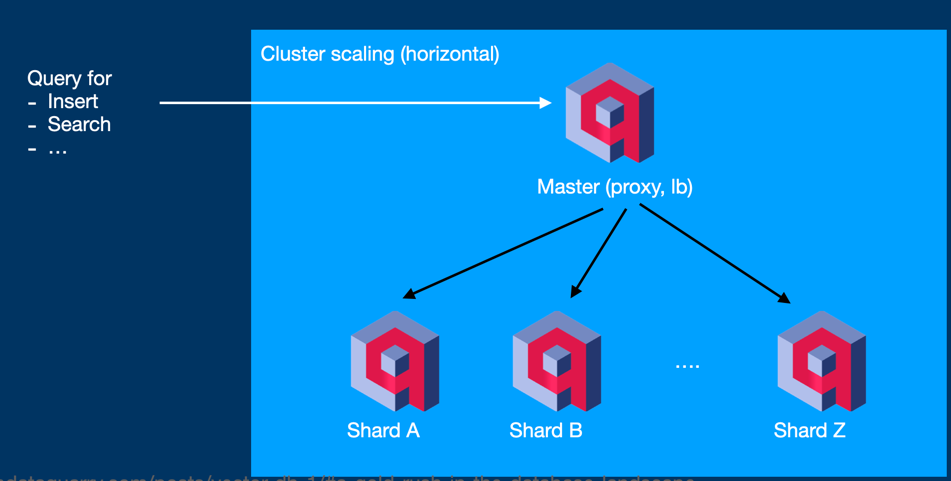
Scaling Challenges in On-Premises Environments
When using a cloud-based solution, the task of scaling, whether up or out, becomes a seamless process that can be effortlessly configured within the cloud console. However, the scenario changes when running Qdrant as a Docker or package system on an on-premises environment, which could be your cloud infrastructure or even your laptop. Qdrant's official documentation provides insights into the scaling process, available here. Scaling out in such cases requires the operation of multiple Qdrant servers, necessitating the configuration of clustering, including the deployment of load balancers or master proxy services.
Pros and Cons of Qdrant
Pros:
User-Friendly: Qdrant shares Pinecone's ease of use, making it accessible to users of various backgrounds.
Open Source Advantage: Being an open-source solution, Qdrant offers the benefit of in-depth investigation and customization when issues arise.
Developer-Friendly: Qdrant caters to developers by allowing it to be run as a package or Docker container on local machines, streamlining the development process.
Memory Efficiency: Developed in Rust, Qdrant exhibits excellent memory efficiency, as demonstrated by a project that successfully loaded 1 GB of raw data into Qdrant running as a package with a total memory usage of only 4.2 GB. This efficiency enables rapid insertion and retrieval of data, especially for relatiely small vector datasets.

Cons:
Scaling Challenges: Scaling out can be a challenging endeavor when deploying Qdrant as a Docker or package system in on-premises environments.
Hybrid Search Limitation: As of the time of writing, Qdrant does not yet support hybrid search, which combines vector search and keyword search capabilities.
References
- What is Pinecone and why use it with your LLMs?
- What is Pinecone AI? A Guide to the Craze Behind Vector Databases
- Vector Databases in Action: Real-World Use Cases and Benefits
- 6 open-source Pinecone alternatives for LLMs
- Chipper Cash thwarts fraudsters in real-time with Pinecone
- Pinecone vs. Chroma: The Pros and Cons
- Distributed deployment