OCR Fundamentals - Part3
📌 Open-source OCR Libraries
Comparison of OCR engines: Tesseract vs EasyOCR
OCR is gaining popularity to improve business efficiency by automatically converting text images, which can be a large number, into textual data. Many OCR tools are available today, which may confuse those who try OCR. This article compares two popular open-source OCR libraries, Tesseract and EasyOCR, after applying the pre-processing techniques we have introduced so far.
Overview of Tesseract
Tesseract is one of the most popular and easy-to-use open-source OCR libraries used by many people for a long time. Version 4 and the newer ones have added an LSTM-based OCR module with 116 additional languages and scripts. The following commands will install Tesseract 4 and its developer tools on Ubuntu, and of course, we can install it on any Linux distribution.
Steps for installing Tesseract:
sudo apt install pytesseract
sudo apt install tesseract-ocr
sudo apt install libtesseract-dev
Sample code:
import cv2
import pytesseract
image = cv2.imread("path_to_image")
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
kernel = np.ones((3,3), np.uint8)
image = cv2.dilate(image, kernel, iterations=1)
image = cv2.GaussianBlur(image, (3, 3), 0)
image = cv2.erode(image, kernel, iterations=1)
cv2.imwrite('path_to_image', image)
text = pytesseract.image_to_string(img, lang="eng")
Overview of EasyOCR
EasyOCR is a python package implemented by PyTorch and supports over 70 languages, and it has the great advantage of customizability. With EasyOCR, we can train document-specific models from scratch. It includes detection and text recognition models, and any of them are deep-learning-based. The detection models locate the bounding boxes where characters are, and then the text recognition modules do their job. Since EasyOCR is deep-learning-based, GPU machines bring better performance.
Steps for installing EasyOCR:
sudo apt install python3-pip
pip3 install easyocr
Sample code:
import easyocr
image = cv2.imread('path_to_img')
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
kernel = np.ones((3,3), np.uint8)
image = cv2.dilate(image, kernel, iterations=1)
image = cv2.GaussianBlur(image, (3, 3), 0)
image = cv2.erode(image, kernel, iterations=1)
cv2.imwrite('path_to_img', image)
reader = easyocr.Reader(['en'], gpu=False)
text = reader.readtext(path_to_image)
Experiment
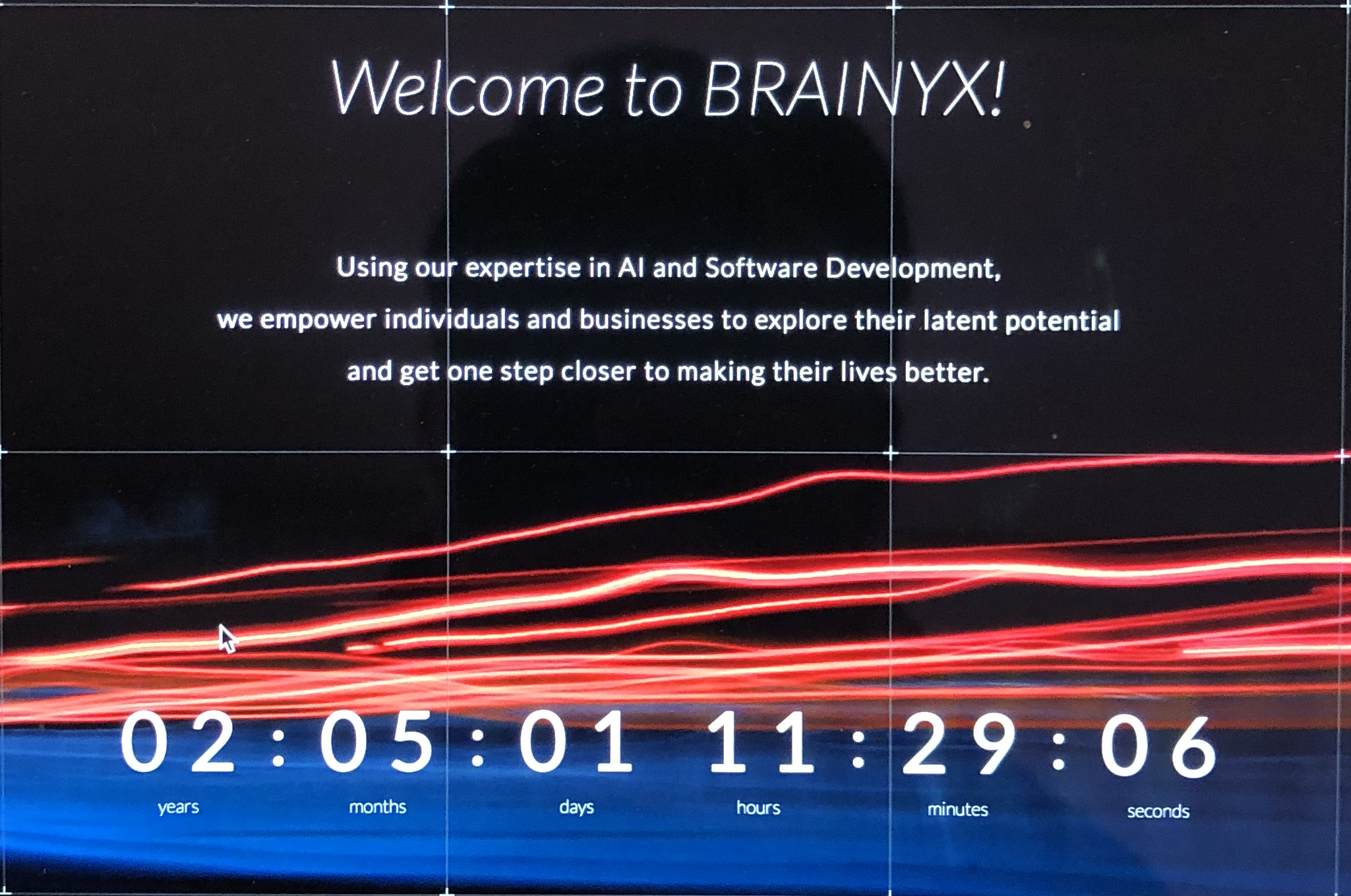
Input Image
Original Image
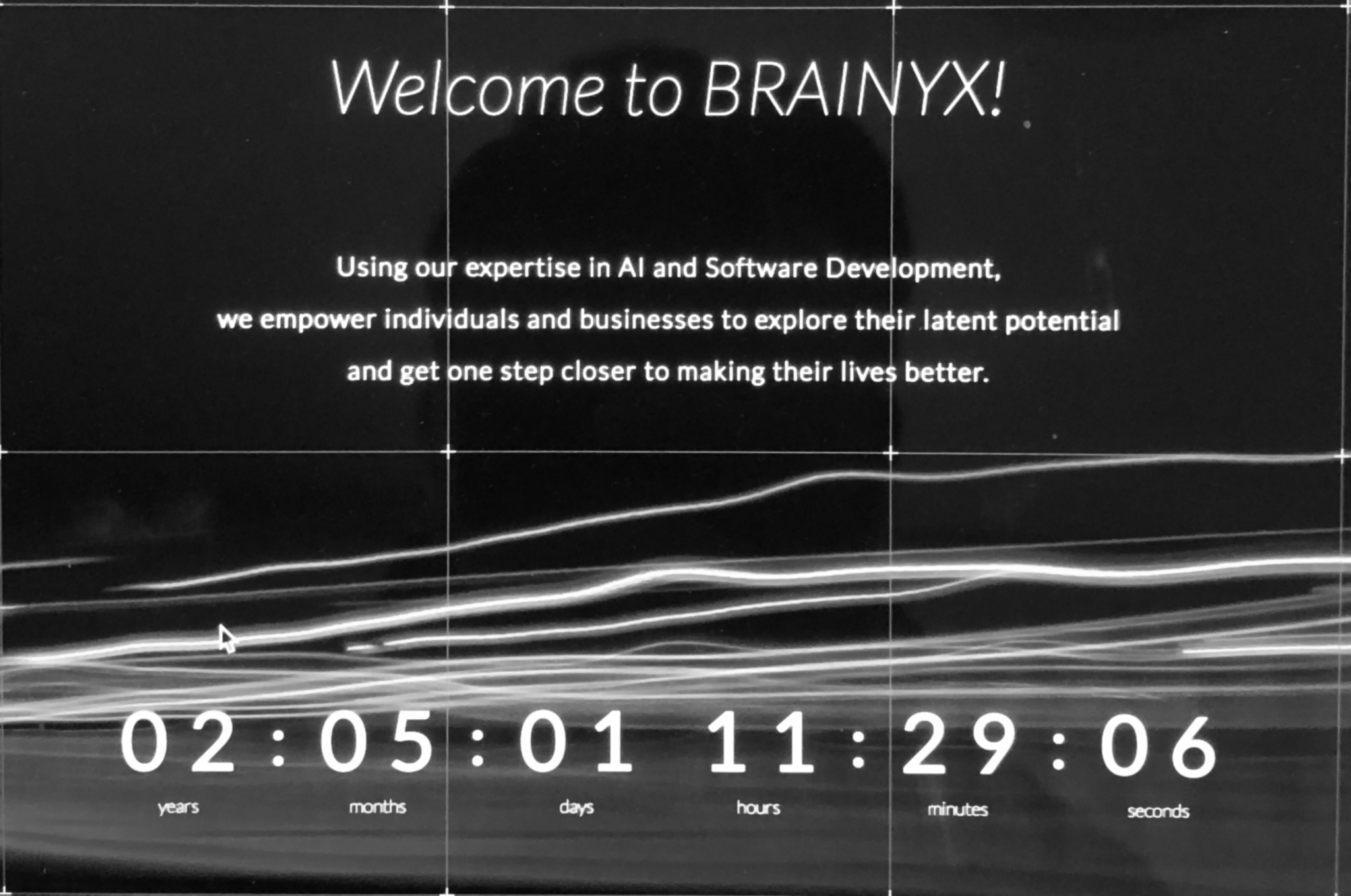
 Pre-processed Image
Pre-processed Image
Output
Original Text
Welcome to BRAINYX!
Using our expertise in AI and Software Development,
we empower individuals and businesses to explore their latent potential
and get one step closer to making their lives better.
02:05:01 11:29:06
years months days hours minutes seconds
Tesseract Output
Welcome to BRAINYX!
Using our expertise in Al and Software Development,
We empower individuals and businesses to explore their latent potential
and get one step closer to making their lives better.
EasyOCR Output
Welcome to BRAINYXI
Using our expertise In Al and Software Development,
we empower individuals and businesses to explore their latent potential
and one step closer to making their lives better:
02:05:01 11:29:06:
years months days hours minutes seconds get
- Execution speed on CPU (seconds)
- Tesseract: 0.777
- EasyOCR: 10.329
- Conclusion Based on our experiment, Tesseract performed better at alphabet recognition, while EasyOCR outperformed on number recognition. Using a combination of them may be an option to get accurate results. Speaking of performance, Tesseract is ok for CPU, but EasyOCR seems to be too slow on CPU and needs machines with GPU.
Summary
Our last three articles have explained the fundamentals of OCR used to extract textual contents from images. OCR helps us to reduce the burden of the cumbersome task of converting printed and handwritten documents into data.
When using OCR, we should consider the number of images to be processed and which library (engine) meets our requirements. Any of the OCR libraries has its advantages and disadvantages. Finally, it is essential to apply proper pre-processing to the original images before passing them to OCR libraries.